背景介绍
Train, Evaluate, Predict(训练,验证,预测):是深度学习中的基础内容,想要完成一个深度学习工程问题,训练,验证,预测是必不可少的环节,今天以LeNet-5模型为例,给入门的小伙伴们提供TensorFlow中三种常用的训练,验证,预测方法。
fit,evaluate,predict(训练,验证,预测)
通过模型的fit方法实现训练过程,evaluate方法实现验证过程,predict方法实现预测过程。这三种方法灵活性较差, 但是很方便,而且可以通过回调函数实现复杂的逻辑控制,是工程应用中经常使用的方法**。fit方法用于训练过程,较为复杂,因此需要设置很多参数,evaluate方法,往往一个epoch或者几个epoch进行一次验证,因此参数比较固定,一般来说只需要验证集数据,其余参数选择默认参数即可。predict方法更加简单,参数也比较固定,一般来说只需要测试集数据,其他参数选择默认参数即可。只有fit方法的参数需要仔细设计,其常用的参数如下:
- x:训练集数据。
- y:训练集标签。
- epochs:达到训练迭代次数epochs停止训练。
- verbose:显示方式,verbose=0,不显示,verbose=1,以进度条显示,verbose=2,每轮迭代显示一次。
- callbacks:回调函数,可以参考我的Callbacks黑科技博客,里面有回调函数的详细使用方法。
- validation_data:验证数据集。
- initial_epoch:开始训练的迭代次数,用于多次阶段性训练中,如迁移学习。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62import tensorflow as tf
import tensorflow.keras as keras
def preprocess(x, y):
x = tf.cast(x, dtype=tf.float32) / 255.
x = tf.reshape(x, (28, 28, 1))
y = tf.one_hot(y, depth=10)
y = tf.cast(y, dtype=tf.int32)
return x, y
if __name__ == '__main__':
(x, y), (x_test, y_test) = keras.datasets.mnist.load_data()
batch_size = 256
tf.random.set_seed(22)
max_epoch = 5
db = tf.data.Dataset.from_tensor_slices((x, y))
db = db.map(preprocess).shuffle(10000).batch(batch_size)
db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test))
db_test = db_test.map(preprocess).batch(batch_size)
# 创建模型
model = keras.Sequential([keras.layers.Conv2D(6, (3, 3), (1, 1), 'same', name='Conv1'),
keras.layers.BatchNormalization(name='Bn1'),
keras.layers.ReLU(name='Relu1'),
keras.layers.MaxPool2D((2, 2), (2, 2), name='Maxpool1'),
keras.layers.Conv2D(16, (3, 3), (1, 1), 'same', name='Conv2'),
keras.layers.BatchNormalization(name='Bn2'),
keras.layers.ReLU(name='Relu2'),
keras.layers.MaxPool2D((2, 2), (2, 2), name='Maxpool2'),
keras.layers.Conv2D(120, (3, 3), (1, 1), 'same', name='Conv3'),
keras.layers.BatchNormalization(name='Bn3'),
keras.layers.ReLU(name='Relu3'),
keras.layers.Flatten(name='Flatten'),
keras.layers.Dense(84, activation='relu', name='Dense1_1'),
keras.layers.Dropout(0.2, name='Dropout'),
keras.layers.Dense(10, activation='softmax', name='Dense2_1')], name='Model')
model.build(input_shape=(None, 28, 28, 1))
model.summary()
optimizer = keras.optimizers.Adam(1e-3)
lossor = keras.losses.CategoricalCrossentropy()
metrics = keras.metrics.CategoricalAccuracy()
model.compile(optimizer=optimizer, loss=lossor, metrics=[metrics])
# 模型训练
model.fit(db, epochs=max_epoch, validation_data=db_test, verbose=2)
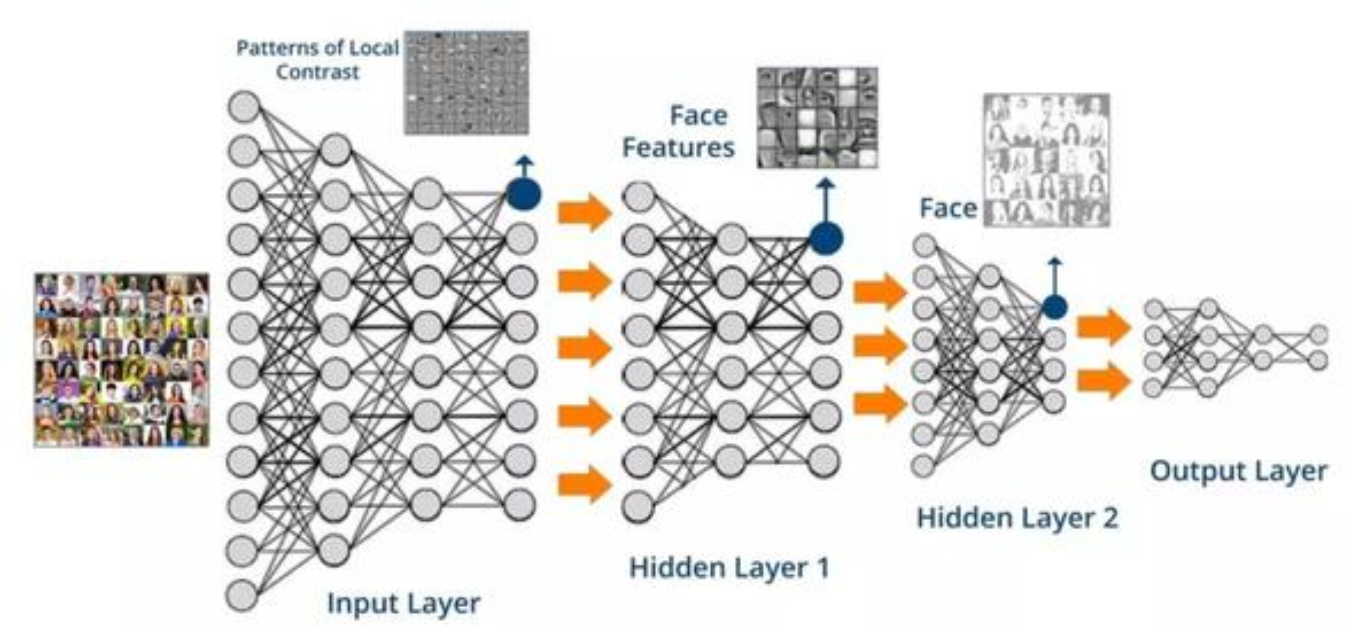
print('----------------------Validation----------------------')
model.evaluate(db_test)
it_test = iter(db_test)
test_x, test_y = next(it_test)
print('----------------------Prediction----------------------')
y_pred = model.predict(test_x)
print('loss: %.6f, categorical_accuracy: %6f' % (lossor(test_y, y_pred), metrics(test_y, y_pred)))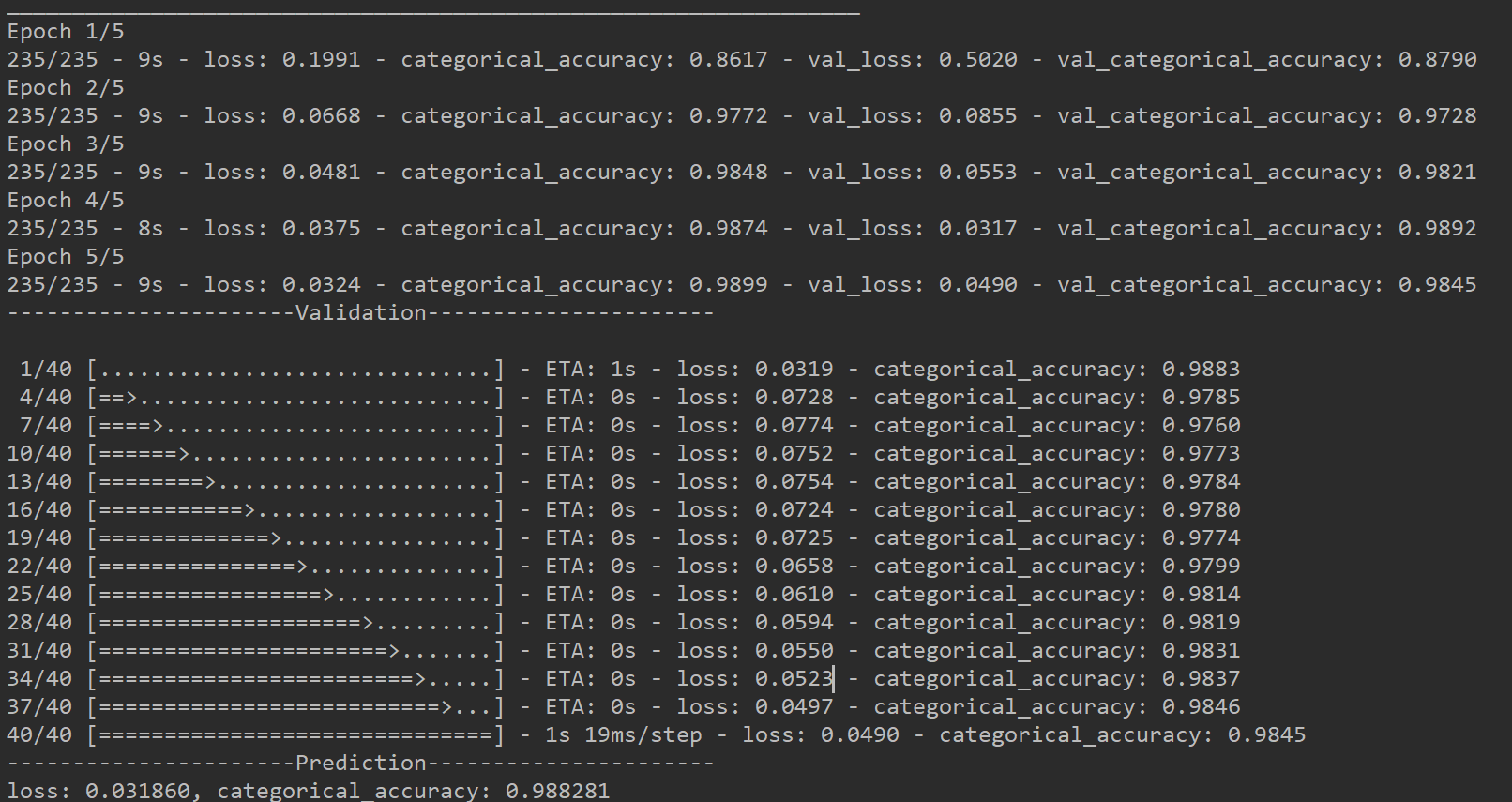
train_on_batch,test_on_batch,predict_on_batch训练,验证和预测方法
通过模型的train_on_batch方法实现训练过程,test_on_batch方法实现验证过程,predict_on_batch方法实现预测过程,相对于fit方法更加灵活, 但是需要手写一些回调方法实现对训练过程的控制,predict_on_batch只有一个参数,只需要输入测试集即可。train_on_batch和test_on_batch常用的参数如下:
- x:训练集或验证集数据。
- y:训练集或验证集标签。
- reset_metrics:是否累积,如果为True则仅适用于该批次,为False则会跨批次累积。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71import tensorflow as tf
import tensorflow.keras as keras
def preprocess(x, y):
x = tf.cast(x, dtype=tf.float32) / 255.
x = tf.reshape(x, (28, 28, 1))
y = tf.one_hot(y, depth=10)
y = tf.cast(y, dtype=tf.int32)
return x, y
if __name__ == '__main__':
(x, y), (x_test, y_test) = keras.datasets.mnist.load_data()
batch_size = 256
tf.random.set_seed(22)
max_epoch = 5
db = tf.data.Dataset.from_tensor_slices((x, y))
db = db.map(preprocess).shuffle(10000).batch(batch_size)
db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test))
db_test = db_test.map(preprocess).batch(batch_size)
# 创建模型
model = keras.Sequential([keras.layers.Conv2D(6, (3, 3), (1, 1), 'same', name='Conv1'),
keras.layers.BatchNormalization(name='Bn1'),
keras.layers.ReLU(name='Relu1'),
keras.layers.MaxPool2D((2, 2), (2, 2), name='Maxpool1'),
keras.layers.Conv2D(16, (3, 3), (1, 1), 'same', name='Conv2'),
keras.layers.BatchNormalization(name='Bn2'),
keras.layers.ReLU(name='Relu2'),
keras.layers.MaxPool2D((2, 2), (2, 2), name='Maxpool2'),
keras.layers.Conv2D(120, (3, 3), (1, 1), 'same', name='Conv3'),
keras.layers.BatchNormalization(name='Bn3'),
keras.layers.ReLU(name='Relu3'),
keras.layers.Flatten(name='Flatten'),
keras.layers.Dense(84, activation='relu', name='Dense1_1'),
keras.layers.Dropout(0.2, name='Dropout'),
keras.layers.Dense(10, activation='softmax', name='Dense2_1')], name='Model')
model.build(input_shape=(None, 28, 28, 1))
model.summary()
optimizer = keras.optimizers.Adam(1e-3)
lossor = keras.losses.CategoricalCrossentropy()
metrics = keras.metrics.CategoricalAccuracy()
model.compile(optimizer=optimizer, loss=lossor, metrics=[metrics])
# 模型训练
for epoch in range(max_epoch):
it_train = iter(db)
it_test = iter(db_test)
model.reset_metrics()
for train_x, train_y in it_train:
train_result = model.train_on_batch(train_x, train_y)
for val_x, val_y in it_test:
val_result = model.test_on_batch(val_x, val_y)
print('epoch: %d, Train loss: %.6f, Train categorical_accuracy: %6f' % (epoch, train_result[0], train_result[1]))
print('epoch: %d, Validation loss: %.6f, Validation categorical_accuracy: %6f' % (epoch, val_result[0], val_result[1]))
it_test = iter(db_test)
test_x, test_y = next(it_test)
y_pred = model.predict_on_batch(test_x)
print('----------------------Prediction----------------------')
print('loss: %.6f, categorical_accuracy: %6f' % (lossor(test_y, y_pred), metrics(test_y, y_pred)))
自定义训练,验证,预测方法
自定义训练不需要对模型进行编译,直接利用优化器和损失函数,利用梯度下降法反向传播迭代参数,灵活度最高,但是难度也最大。
1 | import tensorflow as tf |

小结
这篇博客给小伙伴们介绍了三种常用的训练,验证和预测方法,主要学习第一种和第三种方法,如果为了使用方便则考虑第一种,如果为了模型更加灵活则考虑第三种,希望小伙伴们都可以熟练掌握。